Various OpenShift-related projects
In 2015-2016, while using OpenShift, I developed a few small open-source projects on top of the Kubernetes/OpenShift APIs:
- OpenShift Dashboard
- OpenShift Cucumber
- OpenShift GitHub Hooks
- OpenShift/Git Integration
- OpenShift Flowdock Notifier
OpenShift Dashboard
When I started using OpenShift, I quickly realized that it was missing a global view of the cluster state. In August 2015 I developed a Web Dashboard for visualization of multi-projects resources in OpenShift.
This gave me the opportunity to learn the OpenShift/Kubernetes API early on, and improve my Go skills - by reading the OpenShift and Kubernetes code bases.
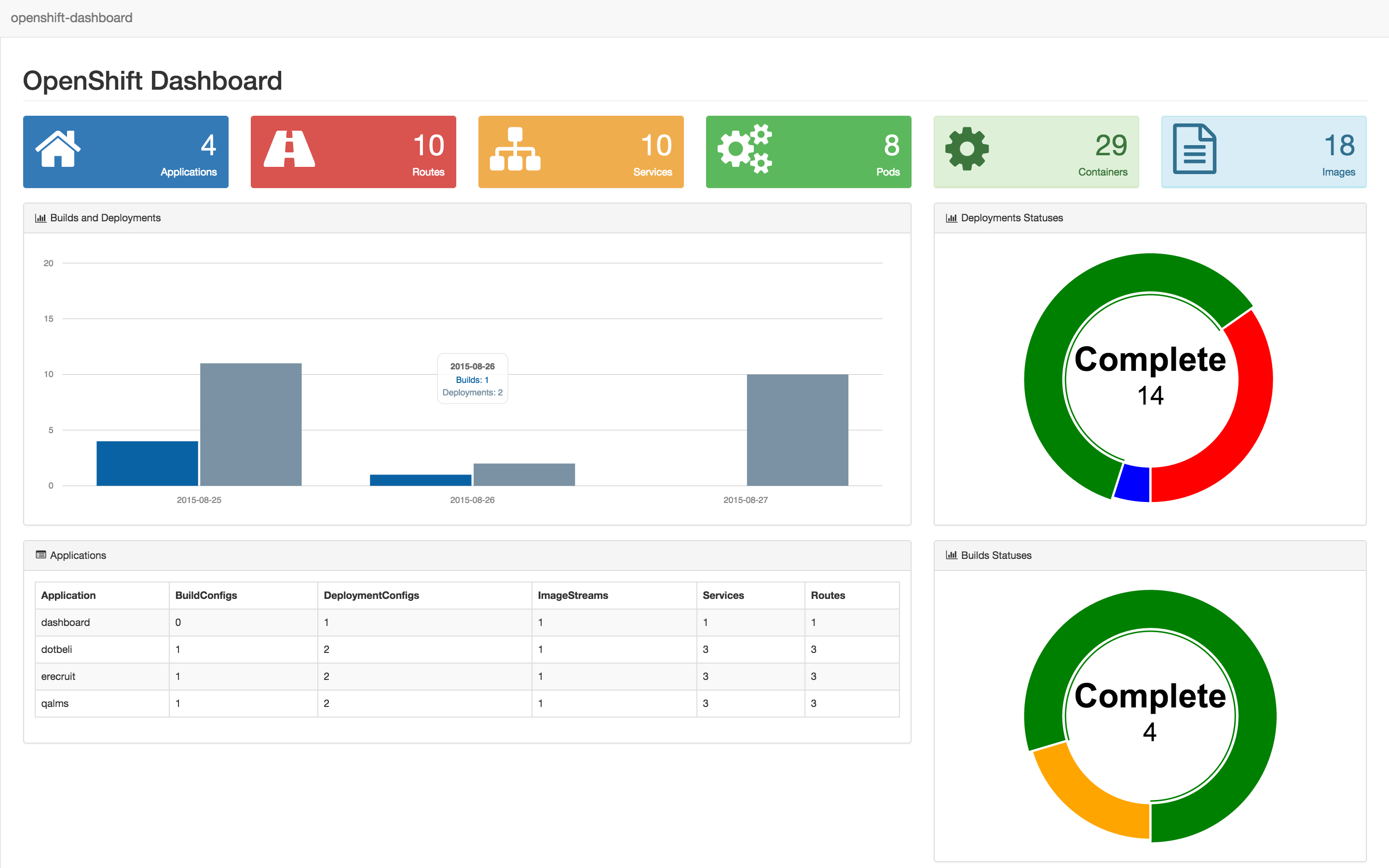
Note that the Kubernetes Dashboard was only created in October 2015 - a few months after this project.
See the project GitHub repository for more information.
OpenShift Cucumber
We had quite a few applications to deploy to on our OpenShift cluster, and found ourselves writing more and more YAML files, to define our applications: deployment configs, but also build configs, OpenShift templates, routes, services, service accounts, roles, secrets, projects, and so on. I wanted to ensure that changes to these files won’t break anything.
Our applications used a variety of languages: Go, Scala, Java, Javascript, so I selected a language-agnostic way to write tests: Cucumber tests, using BDD - Behavior-Driven Development.
This is how I wrote OpenShift Cucumber: a collection of Cucumber steps definitions for the OpenShift and Kubernetes APIs. Think of it as the ancestor of both Helm Chart Tests and the Helm Unit Test plugin - just before Helm was even created.
See the project GitHub repository for more information.
OpenShift GitHub Hooks
This is a Kubernetes “controller” used to automatically manages GitHub hooks for OpenShift BuildConfig triggers. When working on a platform with lots of applications, you don’t want to repeat the same tasks over and over, so you automate. You write tiny scripts first, and then production-ready software. This is a production-ready software we’ve been using to provide a self-service platform to application developers.
See the project GitHub repository for more information.
OpenShift/Git Integration
A Kubernetes “controller” used to automatically import/export OpenShift resources from/to a Git repository. Well, in fact, it only does the “export” part - the “import” was planned but never developed.
The short term goal of this tool was to automatically backup our OpenShift resources in a Git repository, thus enabling audit & history features on top of the Kubernetes API. That part has been developed and worked well, and helped us a lot.
The long term goal - which was never developed - was to do the opposite: read configuration from Git and apply it automatically to our OpenShift cluster. Gitops before the name was even born.
See the project GitHub repository for more information.
OpenShift Flowdock Notifier
We were happy users of Flowdock as our communication tool, mainly for its Inbox feature, which makes it easy to separate communication between people and automatically-generated messages from different tools.
This project is a Kubernetes controller used to send automatic messages to Flowdock based on events happening in the OpenShift cluster. For example to be notified when a build is finished.
It was never finished, I had in mind to use the Kubernetes TPR (Third Party Resources) - the ancestor of the CRD (Custom Resources Definition) - to allow the users to define rules of events that would generate Flowdock notifications.
See the project GitHub repository for more information.
None of these projects are maintained or used anymore.
Project link: https://github.com/vbehar?tab=repositories&q=openshift&type=source